 MENU
MENU 

Can Large Language Models Improve Few-shot Retrieval for Complex Question Answering?
by Muhammad Khalifa (PhD student, Michigan AI)

About the author: I am a Ph.D. student in the CSE and I am also affiliated with Michigan AI Lab. My research revolves around reasoning with language models and controllable generation. This blog post will introduce one of my previous research projects — currently in submission. This project was funded by LG AI research and is done in collaboration with Lajanujen Logeswaran (LG AI), Moontae Lee (LG AI and UIC), and my advisors Lu Wang and Honglak Lee.
Introduction
Answering complex questions is a fundamental aspect of human intelligence. When presented with a question like “What 1988 Christmas comedy film did Brian-Doyle Murray star in?” as humans, we first need to search for movies starring Brian Murray and then identify which of them were released in 1988 during Christmas. Therefore, to answer the previous question we may need to look into the Wikipedia page about Brian Murray to find a list of his movies. Then go through each of them to identify the one released in Christmas 1988 (which is Scrooged). The main challenge is that the facts required to answer such relatively complex questions are often scattered in different locations (web pages, reports, etc.). We need to identify which ones are relevant to answering a given question.
This task is known as multi-hop question answering (MQA for short), where we are given a question and a large corpus of knowledge and we need to answer the question by performing multiple reasoning jumps (i.e., hops) over the corpus to find the answer. Systems trained for this task are typically comprised of two components: a retriever and a reader. The retriever identifies the relevant documents and the reader produces an answer based on the retrieved documents. Throughout this article, we will refer to the set of documents required to answer a given multi-hop question as the document path. For example, the path to answer the above question is the two-hop path Brian Murray → Scrooged.
Our focus here is on the retriever side, whose training requires examples of questions and ground-truth paths. Unfortunately, it is quite expensive to curate large datasets of question-path pairs, especially for low-resource languages or domains. This creates a bottleneck for building MQA systems. One solution is to resort to heuristics for data labeling. However, this can easily lead to incorrect annotation. For instance, if we want to collect the documents required to answer the question above, we may use all the documents that contain the answer i.e., the word “Scrooged” but that can easily lead us to irrelevant documents. While there are existing data-efficient retrieval methods, they are mainly restricted to single-hop QA. That is, answering questions that require only one document, and it is unclear how to extend them to the multi-hop setting. This calls for data-efficient retrieval methods that can easily extend to the multi-hop setting. Enters our approach, dubbed PromptRank.
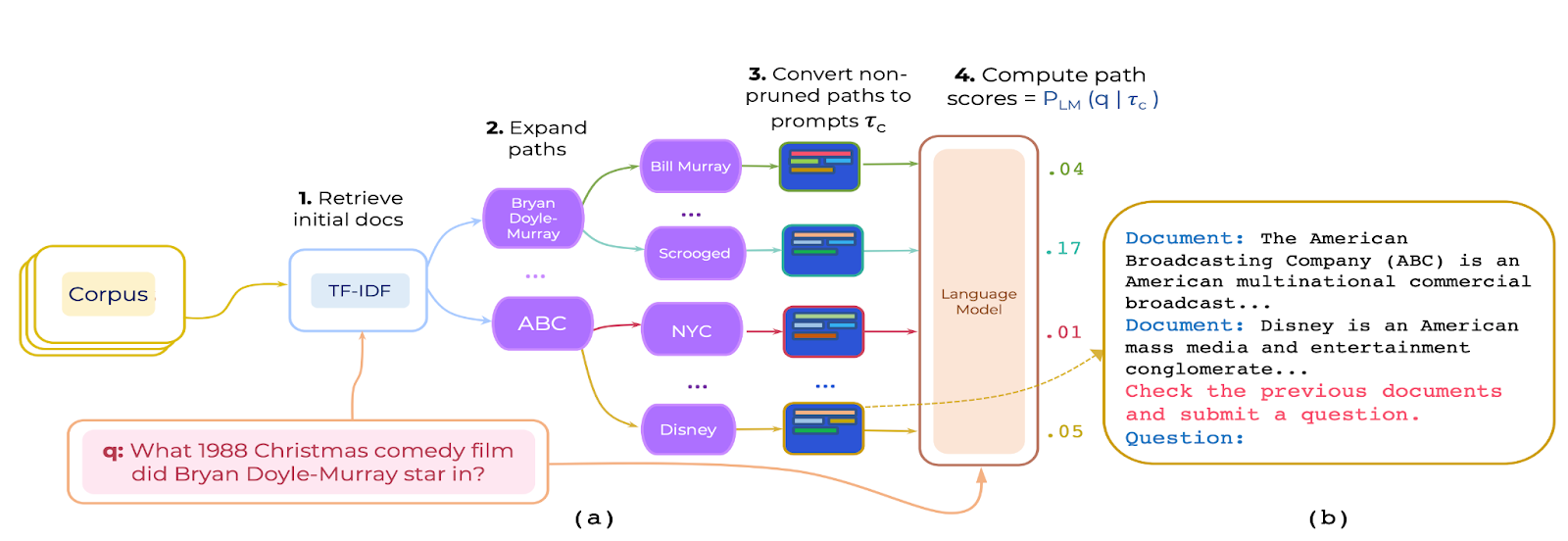
Figure 1: An example of PromptRank on the question “What 1988 Christmas comedy film did Bryan Doyle-Murray star in?”. (a) TF-IDF retrieves potential paths and a language model reranker is used to reweigh the paths based on the probability of generating the question. (b) An example path prompt that includes an instruction (shown in red) and the document paths (shown in black).
PromptRank Overview
PromptRank is inspired by the success of large generative language models trained on massive amounts of data. At its core, PromptRank consists of two steps. First, a simple unsupervised retrieval method picks an initial set of document paths that have the potential to be relevant to the given question. Second, a more complex reranker model reweighs (or reranks) the paths obtained in the first step based on their relevance to the question. The first step is based on a simple unsupervised TF-IDF similarity retrieval. Figure 1. (a) illustrates PromptRank operation on an example question. We will focus on the second step for the remainder of this article.
Scoring Function
The reranker model is given a path and a question and is expected to output a score that represents how relevant the path is to answering the question. This is achieved by computing the conditional likelihood of the question given the path. More precisely, given a question and a path , we compute the relevance score of the path to the question as:
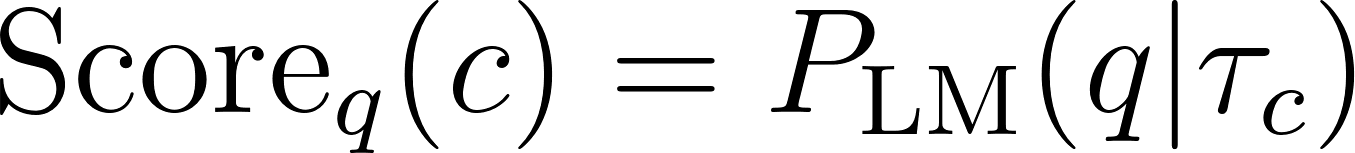
Where is the conditional probability of generating the question given a prompt according to a pretrained language model. We will later discuss how the path prompt is constructed but let’s first discuss the intuition behind this scoring function.
Basically, the scoring function computes some relevancy score between the question and the document path, which is what we want. However, one might claim that the conditional likelihood of the path given the question is more natural. We argue that is preferred over (for some question prompt ) for two reasons. First, aligns with the pretraining process of LMs, where documents are typically followed by FAQs, questionnaires, and commentaries, all of which include questions relevant to the documents. Second, and more importantly, estimating can be difficult since LMs can be sensitive to surface form [1] making it difficult to compare the likelihoods of different reasons paths using . For instance, shorter paths will tend to have a higher likelihood. On the other hand, does not suffer from this issue since we compare the likelihoods of the same sequence i.e., the question.
Path Prompt
Now that we understand the intuition behind the scoring function, let’s dive deep into how it is actually computed. Let’s take the above example. Given the question “What 1988 Christmas comedy film did Brian-Doyle Murray star in?” and the potential two document path consisting of the two documents “ABC” → “Disney”. We first start by constructing a textual prompt that combines an instruction with the content of both documents. The instruction serves as a cue for the language model to nudge it towards assigning higher scores to more relevant paths. One example of an instruction is “Read the previous documents and ask a question”. To obtain performant instructions, we generate a large set of candidate instructions and pick the best-performing ones on a held-out development set. Figure 1 (b) shows how such a prompt would look like for the example we just discussed.
Instruction Ensembling and Other Techniques
To further boost PromptRank performance, we use a set of techniques that have been proposed to improve prompting methods. For instance, we use instruction ensembling, where a set of instructions are used separately to compute a score for a given path, then such scores are aggregated through max or mean ensembling to obtain the final path score. We also use temperature scaling to scale the output logits when computing the question probability. We also leverage the in-context learning ability of language models by showing the LM examples of questions and their ground-truth paths in context.
How well does this work?
To evaluate PromptRank, we compare it to existing fully-supervised systems multi-hop retrieval systems trained on thousands of examples in addition to unsupervised retrieval systems. Figure 2 shows a summary of the performance of PromptRank. Interestingly, with only 128 examples, PromptRank is able to perform closely to fully supervised systems such as PathRetriever [3] and MDR [4] and outperforms DrKit [5].
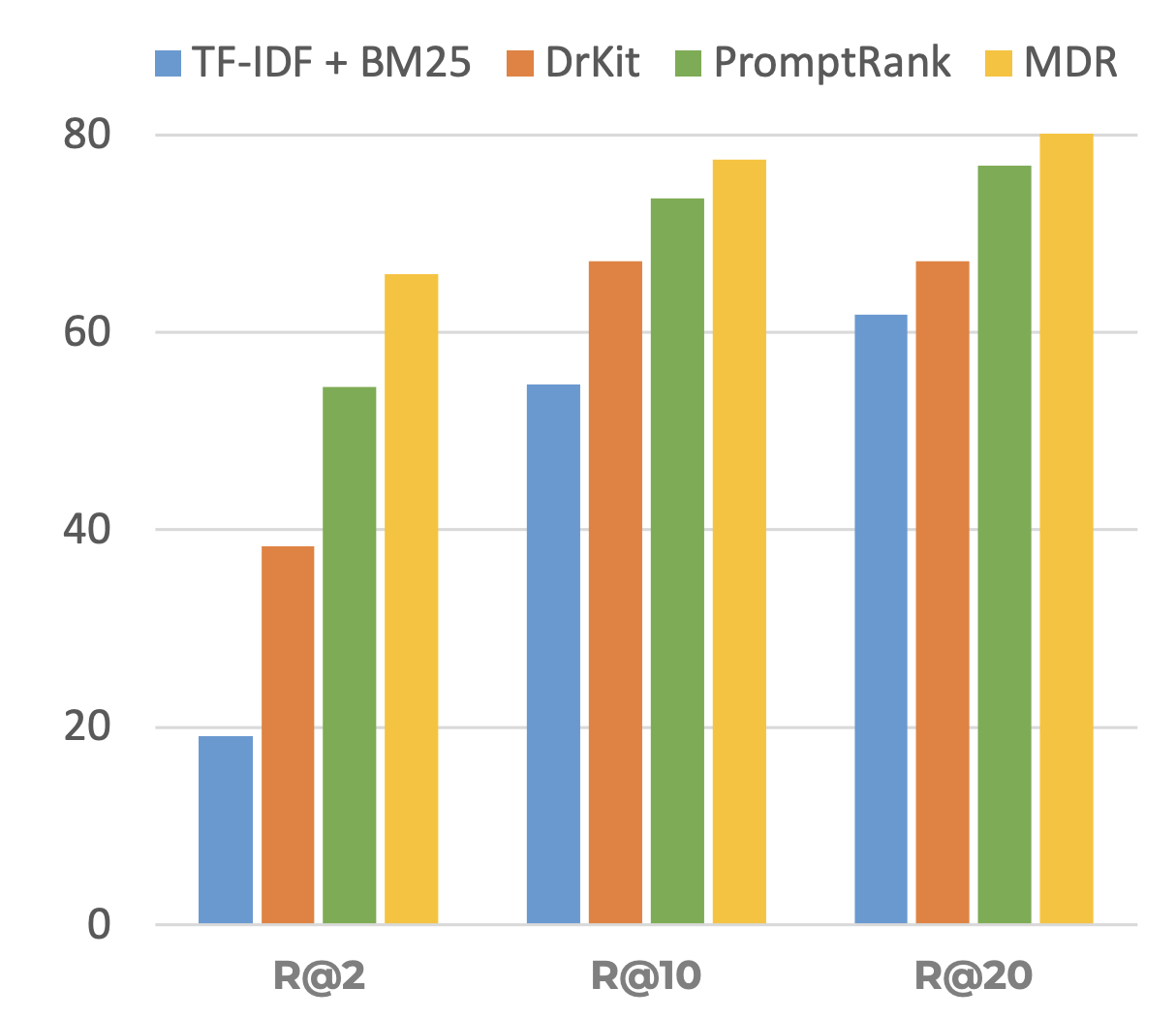
Figure 2: Recall@K of PromptRank compared to unsupervised and fully-supervised systems.
What about the actual QA performance? We also evaluate PromptRank as part of a QA pipeline, where a trained reader model takes as input the paths retrieved by PromptRank and the question and extract the answer span. We compare PromptRank QA performance to fully supervised systems on HotpotQA in terms of the answer exact match (EM) and F1. Table 1 shows the performance, where PromptRank QA performance outperforms or closely matches that of fully-supervised systems.

Table 1: Full QA performance of PromptRank against unsupervised and fully-supervised systems on HotpotQA test set. ICL refers to in-context learning. refers to the number of in-context demonstrations used.
Further Analysis
We perform analysis on the effect of the instruction: whether it instruction improves the retrieval performance, and whether automated instruction search provides any benefit. Figure 2 shows performance over different T5 model sizes with three different types of instructions: a single human-written instruction, the best instruction obtained through automated instruction search, and no instruction. Interestingly, using no instruction performs worst, pointing to the importance of having the instruction part in the prompt. Second, automated instruction search seems to yield more performant instructions than manually crafted instructions.
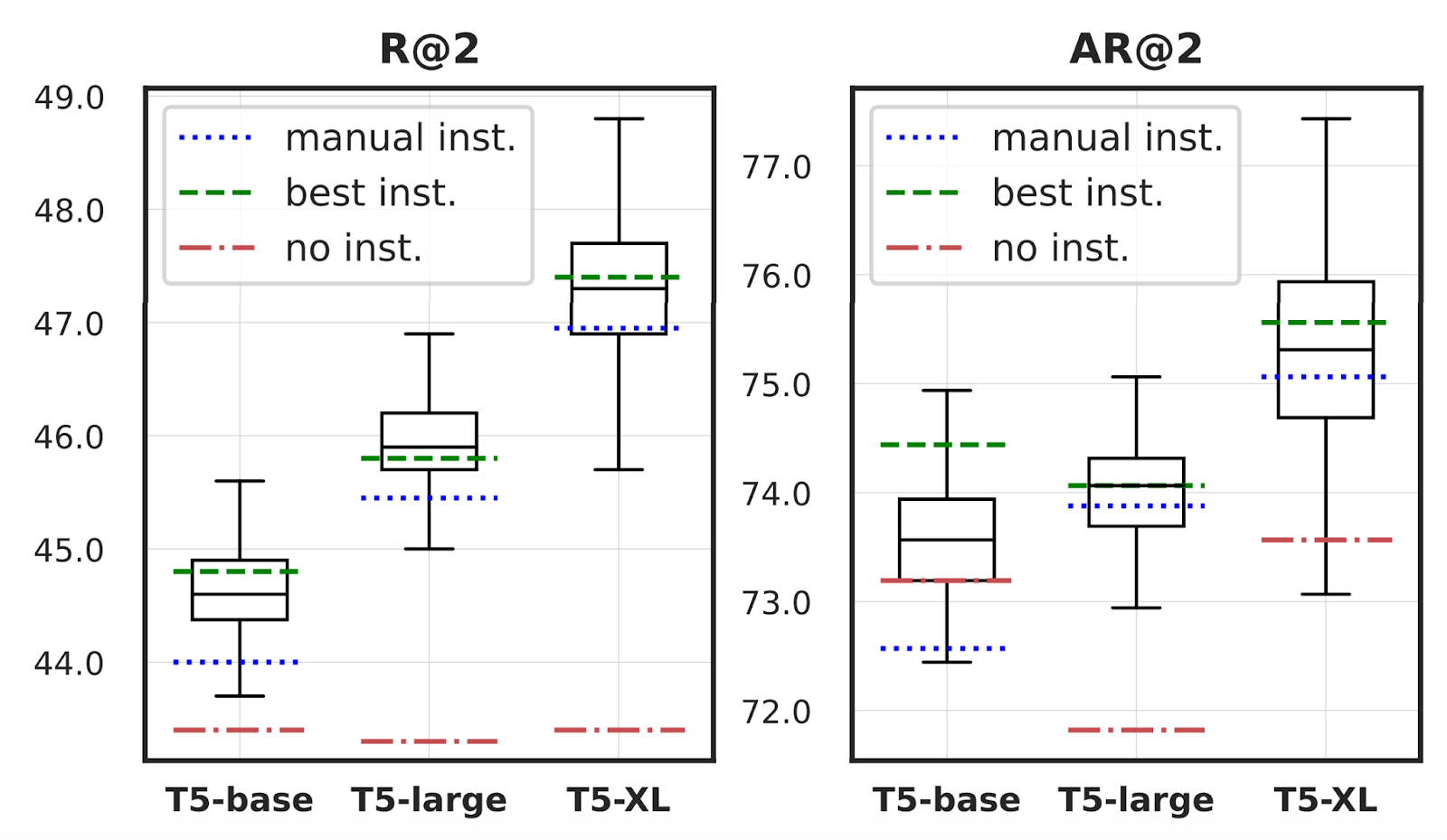
Figure 2: Box plot of R@2 and AR@2 with different kinds of instructions for three different T5 sizes: XL, Large, and Base. The boxplot results are obtained using 200 different instructions.
We perform further analysis on the effect of the instruction location in the prompt, the benefit of joint reasoning over multiple hops, and inference cost using PromptRank. You can read more about that in our preprint, which should be published soon!
Conclusion
In this post, we have presented PromptRank, a few-shot multi-hop reranking system for open-domain QA. PromptRank is based on language model prompting, where the score of the potential document path is computed as the probability of generating the question given some prompt. PromptRank shows impressive few-shot performance compared to state-of-the-art fully supervised multi-hop retrievers while using as few as 128 examples. We further demonstrated the utility of PromptRank as part of a multi-hop QA pipeline, where combining PromptRank with a reader model achieved comparable QA performance to fully-supervised systems.
References
[1] Holtzman, Ari, et al. “Surface Form Competition: Why the Highest Probability Answer Isn’t Always Right.” arXiv preprint arXiv:2104.08315 (2021).
[2] Raffel, Colin, et al. “Exploring the limits of transfer learning with a unified text-to-text transformer.” J. Mach. Learn. Res. 21.140 (2020): 1-67.
[3] Asai, Akari, et al. “Learning to retrieve reasoning paths over Wikipedia graph for question answering.” arXiv preprint arXiv:1911.10470 (2019).
[4] Xiong, Wenhan, et al. “Answering complex open-domain questions with multi-hop dense retrieval.” arXiv preprint arXiv:2009.12756 (2020).
[5] Dhingra, Bhuwan, et al. “Differentiable reasoning over a virtual knowledge base.” arXiv preprint arXiv:2002.10640 (2020).
More about the author
Muhammad Khalifa is a second-year Ph.D. student at Michigan CSE. His research interests involve reasoning with language models, controlled text generation, and reinforcement learning. Muhammad completed his undergraduate studies at Mansoura University, Egypt, and did multiple research internships at Amazon AWS and NAVER Labs Europe.