 MENU
MENU Twenty-two papers by CSE researchers at ACL 2025
Researchers affiliated with Computer Science and Engineering (CSE) at the University of Michigan are presenting 22 papers at the 2025 Annual Meeting of the Association for Computational Linguistics (ACL). The top global conference in computational linguistics, ACL draws thousands of researchers in natural language processing (NLP) and related areas to share the latest findings and developments in the field. This year’s event is taking place in Vienna, Austria, from July 27 to August 1.
New research being presented by CSE authors covers a range of topics in computational linguistics and NLP, including animal vocalization identification, evaluating long-context large language models, multilingual moral reasoning, benchmarking large models’ factuality and bias, and more. The papers being presented are as follows, with the names of authors affiliated with CSE in bold:
Main Conference Papers
Acoustic Individual Identification of White-Faced Capuchin Monkeys Using Joint Multi-Species Embeddings
Álvaro Vega-Hidalgo, Artem Abzaliev, Thore Bergman, Rada Mihalcea
Abstract: Acoustic individual identification of wild animals is an essential task for understanding animal vocalizations within their social contexts, and for facilitating conservation and wildlife monitoring efforts. However, most of the work in this space relies on human efforts, as the development of methods for automatic individual identification is hindered by the lack of data. In this paper, we explore cross-species pre-training to address the task of individual classification in white-faced capuchin monkeys. Using acoustic embeddings from birds and humans, we find that they can be effectively used to identify the calls from individual monkeys. Moreover, we find that joint multi-species representations can lead to further improvements over the use of one representation at a time. Our work demonstrates the potential of cross-species data transfer and multi-species representations, as strategies to address tasks on species with very limited data.

On Many-Shot In-Context Learning for Long-Context Evaluation
Kaijian Zou, Muhammad Khalifa, Lu Wang
Abstract: Many-shot in-context learning (ICL) has emerged as a unique setup to both utilize and test the ability of large language models to handle long context. This paper delves into long-context language model (LCLM) evaluation through many-shot ICL. We first ask: what types of ICL tasks benefit from additional demonstrations, and how effective are they in evaluating LCLMs? We find that classification and summarization tasks show performance improvements with additional demonstrations, while translation and reasoning tasks do not exhibit clear trends. Next, we investigate the extent to which different tasks necessitate retrieval versus global context understanding. We develop metrics to categorize ICL tasks into two groups: (i) similar-sample learning (SSL): tasks where retrieval of the most similar examples is sufficient for good performance, and (ii) all-sample learning (ASL): tasks that necessitate a deeper comprehension of all examples in the prompt. Lastly, we introduce a new many-shot ICL benchmark, MANYICLBENCH, to characterize model’s ability on both fronts and benchmark 12 LCLMs using MANYICLBENCH. We find that while state-of-the-art models demonstrate good performance up to 64k tokens in SSL tasks, many models experience significant performance drops at only 16k tokens in ASL tasks.
Interactive and Expressive Code-Augmented Planning with Large Language Models
Anthony Zhe Liu, Xinhe Wang, Jacob Sansom, Yao Fu, Jongwook Choi, Sungryull Sohn, Jaekyeom Kim, Honglak Lee
Abstract: Large Language Models (LLMs) demonstrate strong abilities in common-sense reasoning and interactive decision-making, but often struggle with complex, long-horizon planning tasks. Recent techniques have sought to structure LLM outputs using control flow and code to improve planning performance. However, code-based approaches can be error-prone and insufficient for handling ambiguous or unstructured data. To address these challenges, we propose REPL-Plan, an LLM planning approach that is fully code-expressive (it can utilize all the benefits of code) while also being dynamic (it can flexibly adapt from errors and use the LLM for soft reasoning). In REPL-Plan, an LLM solves tasks by interacting with a Read-Eval-Print Loop (REPL), which iteratively executes and evaluates code, similar to language shells or interactive code notebooks, allowing the model to flexibly correct errors and handle tasks dynamically. We demonstrate that REPL-Plan achieves strong results across various planning domains compared to previous methods.
Ranking Unraveled: Recipes for LLM Rankings in Head-to-Head AI Combat
Roland Daynauth, Christopher Clarke, Krisztian Flautner, Lingjia Tang, Jason Mars
Abstract: Evaluating large language model (LLM) is a complex task. Pairwise ranking has emerged as state-of-the-art method to evaluate human preferences by having humans compare pairs of LLM outputs based on predefined criteria, enabling ranking across multiple LLMs by aggregating pairwise results through algorithms like Elo. However, applying these ranking algorithms in the context of LLM evaluation introduces several challenges, such as inconsistent ranking results when using ELO. Currently there is a lack of systematic study of those ranking algorithms in evaluating LLMs. In this paper, we explore the effectiveness of ranking systems for head-to-head comparisons of LLMs. We formally define a set of fundamental principles for effective ranking and conduct extensive evaluations on the robustness of several ranking algorithms in the context of LLMs. Our analysis uncovers key insights into the factors that affect ranking accuracy and efficiency, offering guidelines for selecting the most appropriate methods based on specific evaluation contexts and resource constraints.

FactBench: A Dynamic Benchmark for In-the-Wild Language Model Factuality Evaluation
Farima Fatahi Bayat, Lechen Zhang, Sheza Munir, Lu Wang
Abstract: The rapid adoption of language models (LMs) across diverse applications has raised concerns about their factuality, i.e., their consistency with real-world facts. We introduce VERIFY, an evidence-based evaluation pipeline that measures LMs’ factuality in real-world user interactions. VERIFY considers the verifiability of LM-generated content and categorizes content units as Supported, Unsupported, or Undecidable based on Web-retrieved evidence. Importantly, factuality judgment by VERIFY more strongly correlates with human evaluations than existing methods. Using VERIFY, we identify “hallucination prompts,” i.e., those that frequently elicit factual errors in LM responses. These prompts form FactBench, a dataset of 1K prompts spanning 150 topics and tiered into Easy, Moderate, and Hard prompts. We benchmark widely-used openweight and proprietary LMs from six families, yielding three key findings: (i) LMs’ factual precision declines from Easy to Hard prompts, (ii) factuality does not necessarily improve with scale; Llama3.1-405B-Instruct performs comparably to or worse than its 70B variant, and (iii) Gemini1.5-Pro shows a notably higher refusal rate, with over-refusal in 25% of cases.
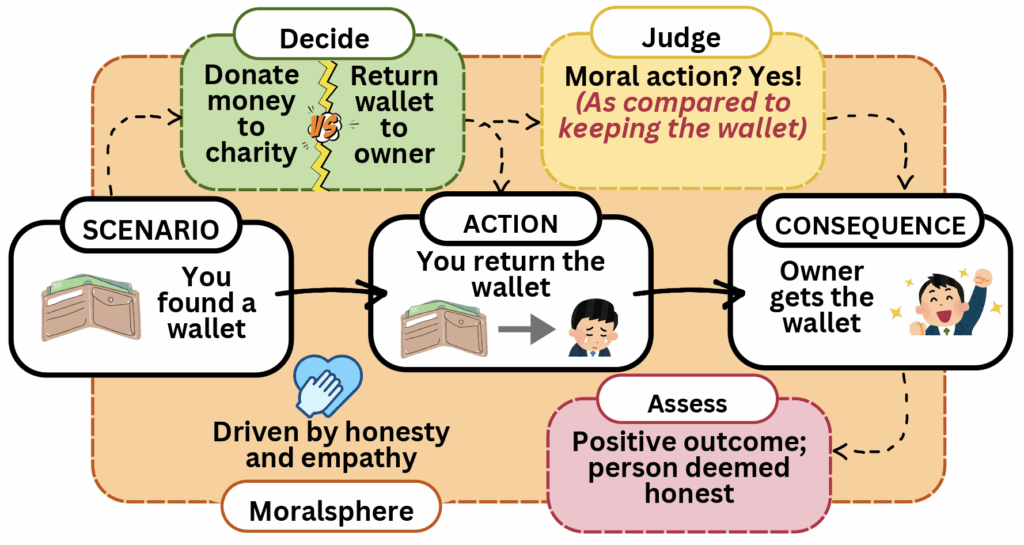
Are Rules Meant to be Broken? Understanding Multilingual Moral Reasoning as a Computational Pipeline with UniMoral
Shivani Kumar, David Jurgens
Abstract: Moral reasoning is a complex cognitive process shaped by individual experiences and cultural contexts and presents unique challenges for computational analysis. While natural language processing (NLP) offers promising tools for studying this phenomenon, current research lacks cohesion, employing discordant datasets and tasks that examine isolated aspects of moral reasoning. We bridge this gap with UniMoral, a unified dataset integrating psychologically grounded and social-media-derived moral dilemmas annotated with labels for action choices, ethical principles, contributing factors, and consequences, alongside annotators’ moral and cultural profiles. Recognizing the cultural relativity of moral reasoning, UniMoral spans six languages, Arabic, Chinese, English, Hindi, Russian, and Spanish, capturing diverse socio-cultural contexts. We demonstrate UniMoral’s utility through a benchmark evaluations of three large language models (LLMs) across four tasks: action prediction, moral typology classification, factor attribution analysis, and consequence generation. Key findings reveal that while implicitly embedded moral contexts enhance the moral reasoning capability of LLMs, there remains a critical need for increasingly specialized approaches to further advance moral reasoning in these models.
Coordinating Chaos: A Structured Review of Linguistic Coordination Methodologies
Benjamin Roger Litterer, David Jurgens, Dallas Card
Abstract: Linguistic coordination—a phenomenon where conversation partners end up having similar patterns of language use—has been established across a variety of contexts and for multiple linguistic features. However, the study of language coordination has been accompanied by a diverse and inconsistently applied set of measures and theoretical perspectives. This diversity has significant consequences, as replication studies have highlighted the brittleness of certain measures and called influential findings into question. While prior work has addressed specific modeling decisions and model types, linguistic coordination research has yet to fully examine, synthesize, and critique the space of modeling choices available. In this work, we present a framework to organize the linguistic coordination literature. Using this schema, we provide a high-level overview of the choices involved in the measurement process and synthesize relevant critiques. Based on both gaps and limitations surfaced from this review, we suggest directions for further exploration and evaluation. In doing so, we provide the clarity required for linguistic coordination research to arrive at interpretable and sound conclusions.
Mapping the Podcast Ecosystem with the Structured Podcast Research Corpus
Benjamin Roger Litterer, David Jurgens, Dallas Card
Abstract: Podcasts provide highly diverse content to a massive listener base through a unique on-demand modality. However, limited data has prevented large-scale computational analysis of the podcast ecosystem. To fill this gap, we introduce a massive dataset of over 1.1M podcast transcripts that is largely comprehensive of all English language podcasts available through public RSS feeds from May and June of 2020. This data is not limited to text, but includes metadata, inferred speaker roles, and audio features and speaker turns for a subset of 370K episodes. Using this data, we conduct a foundational investigation into the content, structure, and responsiveness of this ecosystem. Together, our data and analyses open the door to continued computational research of this popular and impactful medium.
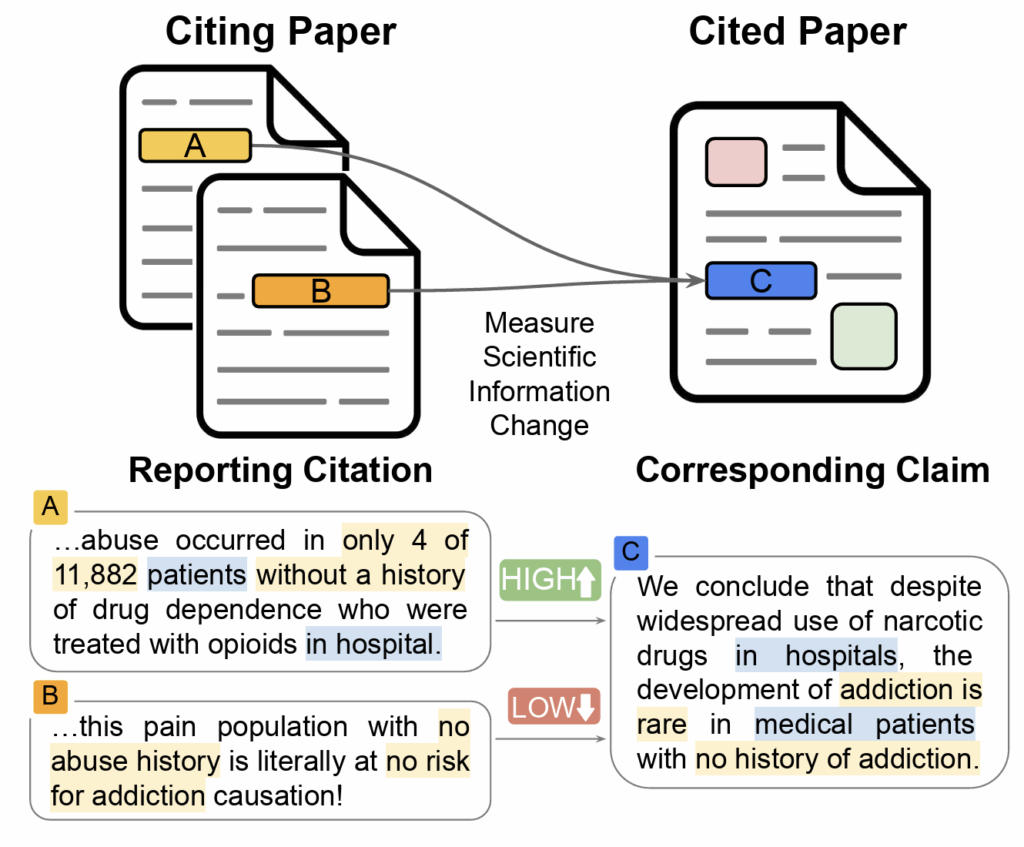
The Noisy Path from Source to Citation: Measuring How Scholars Engage with Past Research
Hong Chen, Misha Teplitskiy, David Jurgens
Abstract: Academic citations are widely used for evaluating research and tracing knowledge flows. Such uses typically rely on raw citation counts and neglect variability in citation types. In particular, citations can vary in their fidelity as original knowledge from cited studies may be paraphrased, summarized, or reinterpreted, possibly wrongly, leading to variation in how much information changes from cited to citing paper. In this study, we introduce a computational pipeline to quantify citation fidelity at scale. Using full texts of papers, the pipeline identifies citations in citing papers and the corresponding claims in cited papers, and applies supervised models to measure fidelity at the sentence level. Analyzing a large-scale multi-disciplinary dataset of approximately 13 million citation sentence pairs, we find that citation fidelity is higher when authors cite papers that are 1) more recent and intellectually close, 2) more accessible, and 3) the first author has a lower H-index and the author team is medium-sized. Using a quasi-experiment, we establish the “telephone effect” – when citing papers have low fidelity to the original claim, future papers that cite the citing paper and the original have lower fidelity to the original. Our work reveals systematic differences in citation fidelity, underscoring the limitations of analyses that rely on citation quantity alone and the potential for distortion of evidence.
Efficient Ensemble for Fine-tuning Language Models on Multiple Datasets
Dongyue Li, Ziniu Zhang, Lu Wang, Hongyang R. Zhang
Abstract: This paper develops an ensemble method for fine-tuning a language model to multiple datasets. Existing methods, such as quantized LoRA (QLoRA), are efficient when adapting to a single dataset. When training on multiple datasets of different tasks, a common setup in practice, it remains unclear how to design an efficient adaptation for fine-tuning language models. We propose to use an ensemble of multiple smaller adapters instead of a single adapter per task. We design an efficient algorithm that partitions n datasets into m groups, where m is typically much smaller than n in practice, and train one adapter for each group before taking a weighted combination to form the ensemble. The algorithm leverages a first-order approximation property of low-rank adaptation to quickly obtain the fine-tuning performances of dataset combinations since methods like LoRA stay close to the base model. Hence, we use the gradients of the base model to estimate its behavior during fine-tuning. Empirically, this approximation holds with less than 1% error on models with up to 34 billion parameters, leading to an estimation of true fine-tuning performances under 5% error while speeding up computation compared to base fine-tuning by 105 times. When applied to fine-tune Llama and GPT models on ten text classification tasks, our approach provides up to 10% higher average test accuracy over QLoRA, with only 9% more FLOPs. On a Llama model with 34 billion parameters, an ensemble of QLoRA increases test accuracy by 3% compared to QLoRA, with only 8% more FLOPs.
Beyond Demographics: Fine-tuning Large Language Models to Predict Individuals’ Subjective Text Perceptions
Matthias Orlikowski, Jiaxin Pei, Paul Röttger, Philipp Cimiano, David Jurgens, Dirk Hovy
Abstract: People naturally vary in their annotations for subjective questions and some of this variation is thought to be due to the person’s sociodemographic characteristics. LLMs have also been used to label data, but recent work has shown that models perform poorly when prompted with sociodemographic attributes, suggesting limited inherent sociodemographic knowledge. Here, we ask whether LLMs can be trained to be accurate sociodemographic models of annotator variation. Using a curated dataset of five tasks with standardized sociodemographics, we show that models do improve in sociodemographic prompting when trained but that this performance gain is largely due to models learning annotator-specific behaviour rather than sociodemographic patterns. Across all tasks, our results suggest that models learn little meaningful connection between sociodemographics and annotation, raising doubts about the current use of LLMs for simulating sociodemographic variation and behaviour.
Findings Papers
Eeyore: Realistic Depression Simulation via Supervised and Preference Optimization
Siyang Liu, Bianca Brie, Wenda Li, Laura Biester, Andrew Lee, James Pennebaker, Rada Mihalcea
Abstract: Large Language Models (LLMs) have been previously explored for mental healthcare training and therapy client simulation, but they still fall short in authentically capturing diverse client traits and psychological conditions. We introduce \textbf{Eeyore}, an 8B model optimized for realistic depression simulation through a structured alignment framework, incorporating expert input at every stage. First, we systematically curate real-world depression-related conversations, extracting depressive traits to guide data filtering and psychological profile construction, and use this dataset to instruction-tune Eeyore for profile adherence. Next, to further enhance realism, Eeyore undergoes iterative preference optimization — first leveraging model-generated preferences and then calibrating with a small set of expert-annotated preferences. Throughout the entire pipeline, we actively collaborate with domain experts, developing interactive interfaces to validate trait extraction and iteratively refine structured psychological profiles for clinically meaningful role-play customization. Despite its smaller model size, the Eeyore depression simulation outperforms GPT-4o with SOTA prompting strategies, both in linguistic authenticity and profile adherence.

Mind the (Belief) Gap: Group Identity in the World of LLMs
Angana Borah, Marwa Houalla, Rada Mihalcea
Abstract: Social biases and belief-driven behaviors can significantly impact Large Language Models (LLMs) decisions on several tasks. As LLMs are increasingly used in multi-agent systems for societal simulations, their ability to model fundamental group psychological characteristics remains critical yet under-explored. In this study, we present a multi-agent framework that simulates belief congruence, a classical group psychology theory that plays a crucial role in shaping societal interactions and preferences. Our findings reveal that LLMs exhibit amplified belief congruence compared to humans, across diverse contexts. We further investigate the implications of this behavior on two downstream tasks: (1) misinformation dissemination and (2) LLM learning, finding that belief congruence in LLMs increases misinformation dissemination and impedes learning. To mitigate these negative impacts, we propose strategies inspired by: (1) contact hypothesis, (2) accuracy nudges, and (3) global citizenship framework. Our results show that the best strategies reduce misinformation dissemination by up to 37% and enhance learning by 11%. Bridging social psychology and AI, our work provides insights to navigate real-world interactions using LLMs while addressing belief-driven biases.
Rethinking Table Instruction Tuning
Naihao Deng, Rada Mihalcea
Abstract: Recent advances in table understanding have focused on instruction-tuning large language models (LLMs) for table-related tasks. However, existing research has overlooked the impact of hyperparameter choices, and also lacks a comprehensive evaluation of the out-of-domain table understanding ability and the general capabilities of these table LLMs. In this paper, we evaluate these abilities in existing table LLMs, and find significant declines in both out-of-domain table understanding and general capabilities as compared to their base models. Through systematic analysis, we show that hyperparameters, such as learning rate, can significantly influence both table-specific and general capabilities. Contrary to the previous table instruction-tuning work, we demonstrate that smaller learning rates and fewer training instances can enhance table understanding while preserving general capabilities. Based on our findings, we introduce TAMA, a TAble LLM instruction-tuned from LLaMA 3.1 8B Instruct, which achieves performance on par with, or surpassing GPT-3.5 and GPT-4 on table tasks, while maintaining strong out-of-domain generalization and general capabilities. Our findings highlight the potential for reduced data annotation costs and more efficient model development through careful hyperparameter selection. We open-source the project and our models.

Chumor 2.0: Towards Better Benchmarking Chinese Humor Understanding
Ruiqi He, Yushu He, Longju Bai, Jiarui Liu, Zhenjie Sun, Zenghao Tang, He Wang, Hanchen Xia, Rada Mihalcea, Naihao Deng
Abstract: Existing humor datasets and evaluations predominantly focus on English, leaving limited resources for culturally nuanced humor in non-English languages like Chinese. To address this gap, we construct Chumor, the first and the largest Chinese humor explanation dataset. Chumor is sourced from Ruo Zhi Ba (RZB, 弱智吧), a Chinese Reddit-like platform known for sharing intellectually challenging and culturally specific jokes. We test ten LLMs through direct and chain-of-thought prompting, revealing that Chumor poses significant challenges to existing LLMs, with their accuracy slightly above random and far below human. In addition, our analysis highlights that human-annotated humor explanations are significantly better than those generated by GPT-4o and ERNIE4-turbo. We release **Chumor** at https://huggingface.co/datasets/MichiganNLP/Chumor, our project page is at https://github.com/MichiganNLP/Chumor-2.0, our leaderboard is at https://huggingface.co/spaces/MichiganNLP/Chumor-leaderboard, and our codebase is at https://github.com/MichiganNLP/Chumor-2.0.
MDBench: A Synthetic Multi-Document Reasoning Benchmark Generated with Knowledge Guidance
Joseph J Peper, Wenzhao Qiu, Ali Payani, Lu Wang
Abstract: Natural language processing evaluation has made significant progress, largely driven by the proliferation of powerful large language models (LLMs). New evaluation benchmarks are of increasing priority as the reasoning capabilities of LLMs are expanding at a rapid pace. In particular, while multi-document (MD) reasoning is an area of extreme relevance given LLM capabilities in handling longer-context inputs, few benchmarks exist to rigorously examine model behavior in this setting. Moreover, the multi-document setting is historically challenging for benchmark creation due to the expensive cost of annotating long inputs. In this work, we introduce MDBench, a new dataset for evaluating LLMs on the task of multi-document reasoning. Notably, MDBench is created through a novel synthetic generation process, allowing us to controllably and efficiently generate challenging document sets and the corresponding question-answer (QA) examples. Our novel technique operates on condensed structured seed knowledge, modifying it through LLM-assisted edits to induce MD-specific reasoning challenges. We then convert this structured knowledge into a natural text surface form, generating a document set and corresponding QA example. We analyze the behavior of popular LLMs and prompting techniques, finding that MDBench poses significant challenges for all methods, even with relatively short document sets. We also see our knowledge-guided generation technique (1) allows us to readily perform targeted analysis of MD-specific reasoning capabilities and (2) can be adapted quickly to account for new challenges and future modeling improvements.
Training Turn-by-Turn Verifiers for Dialogue Tutoring Agents: The Curious Case of LLMs as Your Coding Tutors
Jian Wang, Yinpei Dai, Yichi Zhang, Ziqiao Ma, Wenjie Li, Joyce Chai
Abstract: Intelligent tutoring agents powered by large language models (LLMs) have been increasingly explored to deliver personalized knowledge in areas such as language learning and science education. However, their capabilities in guiding users to solve complex real-world tasks remain underexplored. To address this limitation, in this work, we focus on coding tutoring, a challenging problem that requires tutors to proactively guide students towards completing predefined coding tasks. We propose a novel agent workflow, Trace-and-Verify (TRAVER), which combines knowledge tracing to estimate a student’s knowledge state and turn-by-turn verification to ensure effective guidance toward task completion. We introduce DICT, an automatic evaluation protocol that assesses tutor agents using controlled student simulation and code generation tests. Extensive experiments reveal the challenges of coding tutoring and demonstrate that TRAVER achieves a significantly higher success rate. Although we use code tutoring as an example in this paper, our approach can be extended beyond coding, providing valuable insights into advancing tutoring agents for human task learning.

CliniDial: A Naturally Emerged Multimodal Dialogue Dataset for Team Reflection During Clinical Operation
Naihao Deng, Kapotaksha Das, Rada Mihalcea, Vitaliy Popov, Mohamed Abouelenien
Abstract: In clinical operations, teamwork can be the crucial factor that determines the final outcome. Prior studies have shown that sufficient collaboration is the key factor that determines the outcome of an operation. To understand how the team practices teamwork during the operation, we collected CliniDial from simulations of medical operations. CliniDial includes the audio data and its transcriptions, the simulated physiology signals of the patient manikins, and how the team operates from two camera angles. We annotate behavior codes following an existing framework to understand the teamwork process for CliniDial. We pinpoint three main characteristics of our dataset, including its label imbalances, rich and natural interactions, and multiple modalities, and conduct experiments to test existing LLMs’ capabilities on handling data with these characteristics. Experimental results show that CliniDial poses significant challenges to the existing models, inviting future effort on developing methods that can deal with real-world clinical data. We open-source the codebase at https://github.com/MichiganNLP/CliniDial.
The Million Authors Corpus: A Cross-Lingual and Cross-Domain Wikipedia Dataset for Authorship Verification
Abraham Israeli, Shuai Liu, Jonathan May, David Jurgens
Abstract: Authorship verification (AV) is a crucial task for applications like identity verification, plagiarism detection, and AI-generated text identification. However, datasets for training and evaluating AV models are primarily in English and primarily in a single domain. This precludes analysis of AV techniques for generalizability and can cause seemingly valid AV solutions to, in fact, rely on topic-based features rather than actual authorship features. To address this limitation, we introduce the Million Authors Corpus (), a novel dataset encompassing contributions from dozens of languages on Wikipedia. It includes only long and contiguous textual chunks taken from Wikipedia edits and links those texts to their authors. includes 60.08M textual chunks, contributed by 1.29M Wikipedia authors. It enables broad-scale cross-lingual and cross-domain AV evaluation to ensure accurate analysis of model capabilities that are not overly optimistic. We provide baseline evaluations using state-of-the-art AV models as well as information retrieval models that are not AV-specific in order to demonstrate ‘s unique cross-lingual and cross-domain ablation capabilities.

Revealing Hidden Mechanisms of Cross-Country Content Moderation with Natural Language Processing
Neemesh Yadav, Jiarui Liu, Francesco Ortu, Roya Ensafi, Zhijing Jin, Rada Mihalcea
Abstract: The ability of Natural Language Processing (NLP) methods to categorize text into multiple classes has motivated their use in online content moderation tasks, such as hate speech and fake news detection. However, there is limited understanding of how or why these methods make such decisions, or why certain content is moderated in the first place. To investigate the hidden mechanisms behind content moderation, we explore multiple directions: 1) training classifiers to reverse-engineer content moderation decisions across countries; 2) explaining content moderation decisions by analyzing Shapley values and LLM-guided explanations. Our primary focus is on content moderation decisions made across countries, using pre-existing corpora sampled from the Twitter Stream Grab. Our experiments reveal interesting patterns in censored posts, both across countries and over time. Through human evaluations of LLM-generated explanations across three LLMs, we assess the effectiveness of using LLMs in content moderation. Finally, we discuss potential future directions, as well as the limitations and ethical considerations of this work.
Tokenization is Sensitive to Language Variation
Anna Wegmann, Dong Nguyen, David Jurgens
Abstract: Variation in language is ubiquitous and often systematically linked to regional, social, and contextual factors. Tokenizers split texts into smaller units and might behave differently for less common linguistic forms. This might affect downstream LLM performance differently on two types of tasks: Tasks where the model should be robust to language variation (e.g., for semantic tasks like NLI, labels do not depend on whether a text uses British or American spelling) and tasks where the model should be sensitive to language variation (e.g., for form-based tasks like authorship verification, labels depend on whether a text uses British or American spelling). We pre-train BERT base models with the popular Byte-Pair Encoding algorithm to investigate how key tokenization design choices impact the performance of downstream models: the corpus used to train the tokenizer, the pre-tokenizer and the vocabulary size. We find that the best tokenizer varies on the two task types and that the pre-tokenizer has the biggest overall impact on performance. Further, we introduce a new approach to estimate tokenizer impact on downstream LLM performance, showing substantial improvement over metrics like Rényi efficiency. We encourage more work on language variation and its relation to tokenizers and thus LLM performance.
Evaluating LLMs’ Mathematical and Coding Competency through Ontology-guided Interventions
Pengfei Hong, Navonil Majumder, Deepanway Ghosal, Somak Aditya, Rada Mihalcea, Soujanya Poria
Abstract: Recent advancements in Large Language Models (LLMs) have showcased striking results on existing logical reasoning benchmarks, with some models even surpassing human performance. However, the true depth of their competencies and robustness in reasoning tasks remains an open question. To this end, in this paper, we focus on two popular reasoning tasks: arithmetic reasoning and code generation. Particularly, we introduce (i) a general ontology of perturbations for math and coding questions, (ii) a semi-automatic method to apply these perturbations, and (iii) two datasets, GSMore and HumanEval-Core, respectively, of perturbed math and coding problems to probe LLM capabilities in numeric reasoning and coding tasks. Through comprehensive evaluations of both closed-source and open-source LLMs, we show a significant performance drop across all the models against the perturbed questions, suggesting that the current LLMs lack robust problem solving skills and structured reasoning abilities in many areas, as defined by our ontology.