 MENU
MENU Fifteen papers by CSE researchers at CVPR 2024
Fifteen papers authored by researchers affiliated with CSE have been accepted for presentation at the 2024 IEEE/CVF Computer Vision and Pattern Recognition Conference (CVPR). Taking place June 17-21 in Seattle, WA, CVPR is the premier international conference for new research in computer vision.
Topics covered by CSE researchers at the conference include large language model grounding, inversion-free image editing, 3D scene representation, camera pose estimation, and more.
The following papers are being presented at the conference, with the names of CSE researchers in bold:
“GROUNDHOG: Grounding Large Language Models to Holistic Segmentation”
Yichi Zhang, Ziqiao Ma, Xiaofeng Gao, Suhaila Shakiah, Qiaozi Gao, Joyce Chai
Abstract: Most multimodal large language models (MLLMs) learn language-to-object grounding through causal language modeling where grounded objects are captured by bounding boxes as sequences of location tokens. This paradigm lacks pixel-level representations that are important for fine-grained visual understanding and diagnosis. In this work, we introduce GROUNDHOG, an MLLM developed by grounding Large Language Models to holistic segmentation. GROUNDHOG incorporates a masked feature extractor and converts extracted features into visual entity tokens for the MLLM backbone, which then connects groundable phrases to unified grounding masks by retrieving and merging the entity masks. To train GROUNDHOG, we carefully curated M3G2, a grounded visual instruction tuning dataset with Multi-Modal Multi-Grained Grounding, by harvesting a collection of segmentation-grounded datasets with rich annotations. Our experimental results show that GROUNDHOG achieves superior performance on various language grounding tasks without task-specific fine-tuning, and significantly reduces object hallucination. GROUNDHOG also demonstrates better grounding towards complex forms of visual input and provides easy-to-understand diagnosis in failure cases.

“Inversion-Free Image Editing with Natural Language”
Sihan Xu, Yidong Huang, Jiayi Pan, Ziqiao Ma, Joyce Chai
Abstract: Despite recent advances in inversion-based editing, text-guided image manipulation remains challenging for diffusion models. The primary bottlenecks include 1) the time-consuming nature of the inversion process; 2) the struggle to balance consistency with accuracy; 3) the lack of compatibility with efficient consistency sampling methods used in consistency models. To address the above issues, we start by asking ourselves if the inversion process can be eliminated for editing. We show that when the initial sample is known, a special variance schedule reduces the denoising step to the same form as the multi-step consistency sampling. We name this Denoising Diffusion Consistent Model (DDCM), and note that it implies a virtual inversion strategy without explicit inversion in sampling. We further unify the attention control mechanisms in a tuning-free framework for text-guided editing. Combining them, we present inversion-free editing (InfEdit), which allows for consistent and faithful editing for both rigid and non-rigid semantic changes, catering to intricate modifications without compromising on the image’s integrity and explicit inversion. Through extensive experiments, InfEdit shows strong performance in various editing tasks and also maintains a seamless workflow (less than 3 seconds on one single A40), demonstrating the potential for real-time applications.

“Unsupervised Feature Learning with Emergent Data-Driven Prototypicality”
Yunhui Guo, Youren Zhang, Yubei Chen, Stella X. Yu
Abstract: Given an image set without any labels, our goal is to train a model that maps each image to a point in a feature space such that, not only proximity indicates visual similarity, but where it is located directly encodes how prototypical the image is according to the dataset.
Our key insight is to perform unsupervised feature learning in hyperbolic instead of Euclidean space, where the distance between points still reflect image similarity, and yet we gain additional capacity for representing prototypicality with the location of the point: The closer it is to the origin, the more prototypical it is. The latter property is simply emergent from optimizing the usual metric learning objective: The image similar to many training instances is best placed at the center of corresponding points in Euclidean space, but closer to the origin in hyperbolic space.
We propose an unsupervised feature learning algorithm in Hyperbolic space with sphere pACKing. HACK first generates uniformly packed particles in the Poincaré ball of hyperbolic space and then assigns each image uniquely to each particle. Images after congealing are regarded more typical of the dataset it belongs to. With our feature mapper simply trained to spread out training instances in hyperbolic space, we observe that images move closer to the origin with congealing, validating our idea of unsupervised prototypicality discovery. We demonstrate that our data-driven prototypicality provides an easy and superior unsupervised instance selection to reduce sample complexity, increase model generalization with atypical instances and robustness with typical ones.
“Tactile-Augmented Radiance Fields”
Yiming Dou, Fengyu Yang, Yi Liu, Antonio Loquercio, Andrew Owens
Abstract: We present a scene representation, which we call a tactile-augmented radiance field (TaRF), that brings vision and touch into a shared 3D space. This representation can be used to estimate the visual and tactile signals for a given 3D position within a scene. We capture a scene’s TaRF from a collection of photos and sparsely sampled touch probes. Our approach makes use of two insights: (i) common vision-based touch sensors are built on ordinary cameras and thus can be registered to images using methods from multi-view geometry, and (ii) visually and structurally similar regions of a scene share the same tactile features. We use these insights to register touch signals to a captured visual scene, and to train a conditional diffusion model that, provided with an RGB-D image rendered from a neural radiance field, generates its corresponding tactile signal. To evaluate our approach, we collect a dataset of TaRFs. This dataset contains more touch samples than previous real-world datasets, and it provides spatially aligned visual signals for each captured touch signal. We demonstrate the accuracy of our cross-modal generative model and the utility of the captured visual-tactile data on several downstream tasks.

“FAR: Flexible, Accurate and Robust 6DoF Relative Camera Pose Estimation”
Chris Rockwell, Nilesh Kulkarni, Linyi Jin, Jeong Joon Park, Justin Johnson, David Fouhey
Abstract: Estimating relative camera poses between images has been a central problem in computer vision. Methods that find correspondences and solve for the fundamental matrix offer high precision in most cases. Conversely, methods predicting pose directly using neural networks are more robust to limited overlap and can infer absolute translation scale, but at the expense of reduced precision. We show how to combine the best of both methods; our approach yields results that are both precise and robust, while also accurately inferring translation scales. At the heart of our model lies a Transformer that (1) learns to balance between solved and learned pose estimations, and (2) provides a prior to guide a solver. A comprehensive analysis supports our design choices and demonstrates that our method adapts flexibly to various feature extractors and correspondence estimators, showing state-of-the-art performance in 6DoF pose estimation on Matterport3D, InteriorNet, StreetLearn, and Map-free Relocalization.

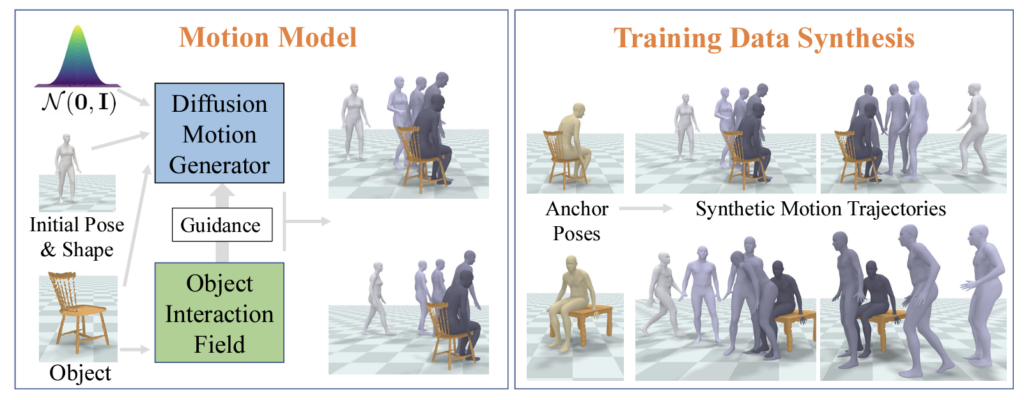
“NIFTY: Neural Object Interaction Fields for Guided Human Motion Synthesis”
Nilesh Kulkarni, Davis Rempe, Kyle Genova, Abhijit Kundu, Justin Johnson, David Fouhey, Leonidas Guibas
We address the problem of generating realistic 3D motions of humans interacting with objects in a scene. Our key idea is to create a neural interaction field attached to a specific object, which outputs the distance to the valid interaction manifold given a human pose as input. This interaction field guides the sampling of an object-conditioned human motion diffusion model, so as to encourage plausible contacts and affordance semantics. To support interactions with scarcely available data, we propose an automated synthetic data pipeline. For this, we seed a pre-trained motion model, which has priors for the basics of human movement, with interaction-specific anchor poses extracted from limited motion capture data. Using our guided diffusion model trained on generated synthetic data, we synthesize realistic motions for sitting and lifting with several objects, outperforming alternative approaches in terms of motion quality and successful action completion. We call our framework NIFTY: Neural Interaction Fields for Trajectory sYnthesis. Project Page with additional results available at this https URL.
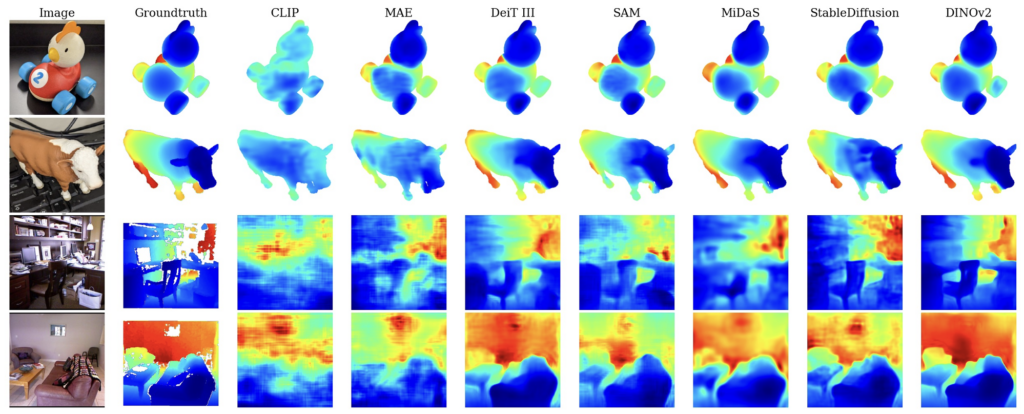
“Probing the 3D Awareness of Visual Foundation Models”
Mohamed El Banani, Amit Raj, Kevis-Kokitsi Maninis, Abhishek Kar, Yuanzhen Li, Michael Rubinstein, Deqing Sun, Leonidas Guibas, Justin Johnson, Varun Jampani
Abstract: Recent advances in large-scale pretraining have yielded visual foundation models with strong capabilities. Not only can recent models generalize to arbitrary images for their training task, their intermediate representations are useful for other visual tasks such as detection and segmentation. Given that such models can classify, delineate, and localize objects in 2D, we ask whether they also represent their 3D structure? In this work, we analyze the 3D awareness of visual foundation models. We posit that 3D awareness implies that representations (1) encode the 3D structure of the scene and (2) consistently represent the surface across views. We conduct a series of experiments using task-specific probes and zero-shot inference procedures on frozen features. Our experiments reveal several limitations of the current models. Our code and analysis can be found at this https URL.
“3DFIRES: Few Image 3D REconstruction for Scenes with Hidden Surfaces”
Linyi Jin, Nilesh Kulkarni, David Fouhey
Abstract: This paper introduces 3DFIRES, a novel system for scene-level 3D reconstruction from posed images. Designed to work with as few as one view, 3DFIRES reconstructs the complete geometry of unseen scenes, including hidden surfaces. With multiple view inputs, our method produces full reconstruction within all camera frustums. A key feature of our approach is the fusion of multi-view information at the feature level, enabling the production of coherent and comprehensive 3D reconstruction. We train our system on non-watertight scans from large-scale real scene dataset. We show it matches the efficacy of single-view reconstruction methods with only one input and surpasses existing techniques in both quantitative and qualitative measures for sparse-view 3D reconstruction.
“Binding Touch to Everything: Learning Unified Multimodal Tactile Representations”
Fengyu Yang, Chao Feng, Ziyang Chen, Hyoungseob Park, Daniel Wang, Yiming Dou, Ziyao Zeng, Xien Chen, Suchisrit Gangopadhyay, Andrew Owens, Alex Wong
Abstract: The ability to associate touch with other modalities has huge implications for humans and computational systems. However, multimodal learning with touch remains challenging due to the expensive data collection process and non-standardized sensor outputs. We introduce UniTouch, a unified tactile model for vision-based touch sensors connected to multiple modalities, including vision, language, and sound. We achieve this by aligning our UniTouch embeddings to pretrained image embeddings already associated with a variety of other modalities. We further propose learnable sensor-specific tokens, allowing the model to learn from a set of heterogeneous tactile sensors, all at the same time. UniTouch is capable of conducting various touch sensing tasks in the zero-shot setting, from robot grasping prediction to touch image question answering. To the best of our knowledge, UniTouch is the first to demonstrate such capabilities.

“From Isolated Islands to Pangea: Unifying Semantic Space for Human Action Understanding”
Yonglu Li, Xiaoqian Wu, Xinpeng Liu, Zehao Wang, Yiming Dou, Yikun Ji, Junyi Zhang, Yixing Li, Xudong Lu, Jingru Tan, Cewu Lu
Abstract: Action understanding has attracted long-term attention. It can be formed as the mapping from the physical space to the semantic space. Typically, researchers built datasets according to idiosyncratic choices to define classes and push the envelope of benchmarks respectively. Datasets are incompatible with each other like “Isolated Islands” due to semantic gaps and various class granularities, e.g., do housework in dataset A and wash plate in dataset B. We argue that we need a more principled semantic space to concentrate the community efforts and use all datasets together to pursue generalizable action learning. To this end, we design a structured action semantic space given verb taxonomy hierarchy and covering massive actions. By aligning the classes of previous datasets to our semantic space, we gather (image/video/skeleton/MoCap) datasets into a unified database in a unified label system, i.e., bridging “isolated islands” into a “Pangea”. Accordingly, we propose a novel model mapping from the physical space to semantic space to fully use Pangea. In extensive experiments, our new system shows significant superiority, especially in transfer learning. Our code and data will be made public at this https URL.
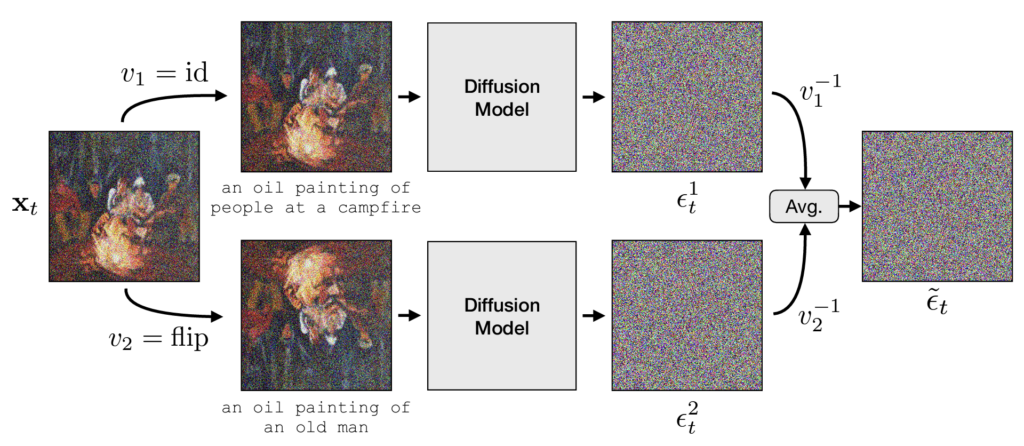
“Visual Anagrams: Generating Multi-View Optical Illusions with Diffusion Models”
Daniel Geng, Inbum Park, Andrew Owens
Abstract: We address the problem of synthesizing multi-view optical illusions: images that change appearance upon a transformation, such as a flip or rotation. We propose a simple, zero-shot method for obtaining these illusions from off-the-shelf text-to-image diffusion models. During the reverse diffusion process, we estimate the noise from different views of a noisy image, and then combine these noise estimates together and denoise the image. A theoretical analysis suggests that this method works precisely for views that can be written as orthogonal transformations, of which permutations are a subset. This leads to the idea of a visual anagram–an image that changes appearance under some rearrangement of pixels. This includes rotations and flips, but also more exotic pixel permutations such as a jigsaw rearrangement. Our approach also naturally extends to illusions with more than two views. We provide both qualitative and quantitative results demonstrating the effectiveness and flexibility of our method. Please see our project webpage for additional visualizations and results: this https URL.
“4D-fy: Text-to-4D Generation Using Hybrid Score Distillation Sampling”
Sherwin Bahmani, Ivan Skorokhodov, Victor Rong, Gordon Wetzstein, Leonidas Guibas, Peter Wonka, Sergey Tulyakov, Jeong Joon Park, Andrea Tagliasacchi, David B. Lindell
Abstract: Recent breakthroughs in text-to-4D generation rely on pre-trained text-to-image and text-to-video models to generate dynamic 3D scenes. However, current text-to-4D methods face a three-way tradeoff between the quality of scene appearance, 3D structure, and motion. For example, text-to-image models and their 3D-aware variants are trained on internet-scale image datasets and can be used to produce scenes with realistic appearance and 3D structure — but no motion. Text-to-video models are trained on relatively smaller video datasets and can produce scenes with motion, but poorer appearance and 3D structure. While these models have complementary strengths, they also have opposing weaknesses, making it difficult to combine them in a way that alleviates this three-way tradeoff. Here, we introduce hybrid score distillation sampling, an alternating optimization procedure that blends supervision signals from multiple pre-trained diffusion models and incorporates benefits of each for high-fidelity text-to-4D generation. Using hybrid SDS, we demonstrate synthesis of 4D scenes with compelling appearance, 3D structure, and motion.

“CurveCloudNet: Processing Point Clouds with 1D Structure”
Colton Stearns, Alex Fu, Jiateng Liu, Jeong Joon Park, Davis Rempe, Despoina Paschalidou, Leonidas Guibas
Abstract: Modern depth sensors such as LiDAR operate by sweeping laser-beams across the scene, resulting in a point cloud with notable 1D curve-like structures. In this work, we introduce a new point cloud processing scheme and backbone, called CurveCloudNet, which takes advantage of the curve-like structure inherent to these sensors. While existing backbones discard the rich 1D traversal patterns and rely on generic 3D operations, CurveCloudNet parameterizes the point cloud as a collection of polylines (dubbed a “curve cloud”), establishing a local surface-aware ordering on the points. By reasoning along curves, CurveCloudNet captures lightweight curve-aware priors to efficiently and accurately reason in several diverse 3D environments. We evaluate CurveCloudNet on multiple synthetic and real datasets that exhibit distinct 3D size and structure. We demonstrate that CurveCloudNet outperforms both point-based and sparse-voxel backbones in various segmentation settings, notably scaling to large scenes better than point-based alternatives while exhibiting improved single-object performance over sparse-voxel alternatives. In all, CurveCloudNet is an efficient and accurate backbone that can handle a larger variety of 3D environments than past works.
“Reconstructing Hands in 3D with Transformers”
Georgios Pavlakos, Dandan Shan, Ilija Radosavovic, Angjoo Kanazawa, David Fouhey, Jitendra Malik
Abstract: We present an approach that can reconstruct hands in 3D from monocular input. Our approach for Hand Mesh Recovery, HaMeR, follows a fully transformer-based architecture and can analyze hands with significantly increased accuracy and robustness compared to previous work. The key to HaMeR’s success lies in scaling up both the data used for training and the capacity of the deep network for hand reconstruction. For training data, we combine multiple datasets that contain 2D or 3D hand annotations. For the deep model, we use a large scale Vision Transformer architecture. Our final model consistently outperforms the previous baselines on popular 3D hand pose benchmarks. To further evaluate the effect of our design in non-controlled settings, we annotate existing in-the-wild datasets with 2D hand keypoint annotations. On this newly collected dataset of annotations, HInt, we demonstrate significant improvements over existing baselines.

“PointInfinity: Resolution-Invariant Point Diffusion Models”
Zixuan Huang, Justin Johnson, Shoubhik Debnath, James Rehg, Chao-Yuan Wu
Abstract: We present PointInfinity, an efficient family of point cloud diffusion models. Our core idea is to use a transformer-based architecture with a fixed-size, resolution-invariant latent representation. This enables efficient training with low-resolution point clouds, while allowing high-resolution point clouds to be generated during inference. More importantly, we show that scaling the test-time resolution beyond the training resolution improves the fidelity of generated point clouds and surfaces. We analyze this phenomenon and draw a link to classifier-free guidance commonly used in diffusion models, demonstrating that both allow trading off fidelity and variability during inference. Experiments on CO3D show that PointInfinity can efficiently generate high-resolution point clouds (up to 131k points, 31 times more than Point-E) with state-of-the-art quality.