 MENU
MENU 

Personal Robots: Why is perception important?

Personal robots are more and more in the media spotlight including movies. Owning a personal robot, your very own maid or butler that has it all, is everyone’s dream. But exactly how advanced are they these days? In my Ph.D. program, I, along with my colleagues are exploring ways to enable a robot to perform tasks that involve sequentially manipulating objects and working in complex indoor environments. But first let’s get to know some of the challenges.
Robots cannot really see
“Robot and Frank” is a movie set in the near future, where a robot butler helps old Frank by cleaning, cooking and keeping him busy with a hobby of his interest. The robot in this movie, which will be referred to as Frank’s robot in this article, is capable of doing all the activities one would like a butler to do in a typical household environment. However, in reality our robots cannot see the world like humans do. We have had tremendous success in making robots function efficiently where the environment is structured, such as warehouse autonomous navigation (Figure 1(a)) or industrial manufacturing (Figure 1(b)). The imposed structure complements the inability of the robots to perceive their environments. However, our household environments are highly unstructured, inherently complex with variety of objects, interactions and relations, and associations to indoor locations. Given a task in such unstructured environments, the robot butler should know what objects are involved, where they are, and how to grasp and move them around to accomplish the task. Hence, robotic perception under unstructured environments is challenging and largely unsolved. In order to achieve this goal of having a robot butler that is capable of cooking a meal at Frank’s place, the problem of perception under complex unstructured indoor environments should be addressed.


Perception for everything
Autonomous personal robots are expected to: a) navigate gracefully in indoor environments avoiding people and, moving with ease through stairs, b) interact with humans beyond question and answering, to intimately serve people with disabilities through physical interactions, c) grasping and manipulating everyday objects to accomplish household tasks; for example, fetching milk cartons and cereal boxes out of a fridge and a shelf respectively, and performing pouring actions to accomplish the breakfast preparation task. In addition to the above mentioned abilities, there are many others that have to be put together before the robot can help Frank. However, all these aspects require the robot to see and perceive the world like humans in order to make any decision. As one can understand there are levels of perceptual information (milk carton is in the fridge inside the kitchen) inferred from sensor observations that need to be combined together to enable the robot make high-level decision over a task (breakfast preparation). In this article, we discuss some of the problems in the domain of goal-driven tasks that involves perception continually to inform sequential manipulation actions, and research efforts towards addressing them.
Perception for manipulation
Every task an autonomous agent is given, can be associated with a goal representation. This representation defines the conditions the agent has to satisfy to accomplish a goal. For example, in breakfast preparation, the desired goal is to have a bowl on a dining table, containing milk and cereal. In order to get to this state, the robot has to sense and perceive what the current state of the world is. In other words, to know where the bowl, milk-carton and cereal box are, and where the objects containing these objects, such as fridge and cabinets are. This has to be followed by actions such as grasping (grab the milk carton) and manipulating (pour the milk into the bowl) these objects in order to accomplish the task.
One thing to note is that household tasks such as meal preparation demand advancements in both hardware (grippers and manipulators) and software AI algorithms. Hardware robotic platforms are capable of performing complex manipulation actions as shown in Figure 2. Combining these advancements in the hardware platforms with AI algorithms can enable the robots to perform goal-directed task executions (Figure. 2(a)). However in order to bring these platforms to home environments which are often cluttered as shown in Figure 2b, the ability to perceive under ambiguous observations have to be improved.


Additionally, perceiving the world is extremely challenging, especially when the robot needs to act and change the world in order to complete a task. Things like noisy sensor data and extremely varying environmental conditions with wide range of object categories, make robot perception a real bottleneck in bringing personal robots to the home.
The clutter challenge
Human environments are often cluttered, making it challenging to perceive using the existing robot sensors. Clutter can be defined to be ambiguity created in the observations due to environmental occlusions, making it harder to identify objects in the world. A typical kitchen scene captured using a RGB camera will result in observation as shown in Figure 3a. As one can notice that objects such as coffee maker are not directly visible to the camera from this particular viewpoint. Similarly, the kitchen sink captured using a RGB camera as shown in Figure 3b, has extreme clutter with wide range of objects in arbitrary poses. Speaking of variety of objects, the objects that have functional parts such as fridge, oven and coffee makers as shown in Figure 3c. These scenarios are very common and lead to incomplete sensor observation about the world. Perceiving and reasoning under such ambiguous and incomplete information towards a household task is challenging. To emphasize, take a second look at Figure 5b, and consider a task where the robot needs to pick up all the objects from the sink and put it in a dishwasher. At the minimum, this task requires the robot to decide which object it needs to pick up next. Hence, it should perceive what objects are in the sink and how they are physically supporting each other to know which object is the target object for the pick up action. This task is challenging in and itself, however becomes much harder under incomplete sensor observation due to clutter.

Levels of perception
A robot that is built with various components needs to possess proprioception (sense of relative position of one’s own body parts) along with an estimate of its relative position in an environment. For example, the robot should be able to estimate that “it is near the kitchen sink” in a familiar home environment. In addition to this notion of self localization in an environment, the robot should be able to perceive the state of the world and abstract the perceived information to perform tasks. For example, the robot must perceive where the dining table, plates, and cutlery are in order to set the table for dinner.
A robot can understand the world at different levels. A high level understanding can result in representing a world as a collection of semantic place locations (living room, bed room and dining room) that will let the robot navigate to a desired location (dining table in the dining room) (Figure. 4). A low level abstraction could result in collection of objects (Figure. 5) with their positions and orientations, suitable for grasping the objects for completing a task.


The scene understanding towards these levels of abstractions becomes extremely challenging when the sensor observations are noisy and can only capture partial information about the environment at every instant.
Our advancements
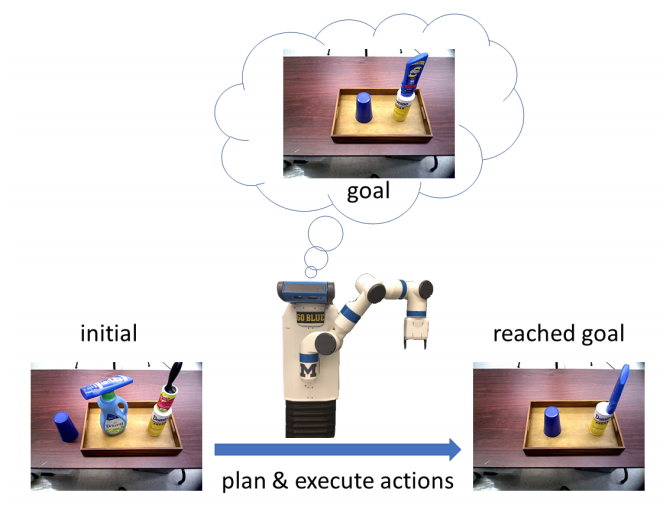
With our research advancements, I along with my colleagues are developing efficient ways to overcome these challenges posed by complex indoor environments. For example, if the task is to set the table for dinner, then the robot can associate a goal state with conditions such as table is clean, one plate on the table in front of each chair, fork on the left of each plate, and spoon on the right of each plate. Achieving this goal state would mean that the robot accomplishes the task. The initial state provided to the robot is arbitrary and can have a messy table, or plates and cutlery in shelves. This arbitrary initial state has to be perceived and abstracted appropriately to symbols and axioms (table is not clean, plates are in shelves, forks are in drawer, and spoons are in the drainer ), such that the robot can plan actions that would lead to the associated goal state. However, perceiving this arbitrary state to enable task planning to pick and place objects is non-trivial. As a step towards solving this problem Zeng et. al. [1] developed an approach that lets the robot perceive the desired goal state (a tray with 3 objects in a specific configuration) shown by the user (see Figure. 6). And at a later point when the robot is provided with an arbitrary scene (a tray and 5 objects in some configuration), it perceives the current state and plans a sequence of actions to realize the desired goal state.
To perform this type of goal-driven tasks under inherent clutterness of the indoor environments, we enable the robot to perceive the world by developing algorithms that considers all possible hypothesis (generative approach [2]) to produce a most likely world state that explains the sensor observation of the robot [3, 4]. These hypothesis include plausible objects and their poses in the real world that is likely to produce the sensor observation of the world.
In order to extend these inference methods beyond table scenes (where the robot has to navigate to kitchen and open a fridge to fetch a milk carton in order to complete a task), we are developing algorithms that are scalable to a large number and variety of objects with functional parts (cabinets and other articulated objects – Figure 7) [5, 6].

Furthermore, contextual reasoning (milk carton is most likely to be found in fridge) enables the robot to make intelligent decisions when searching for objects in the human environments. We explore ways the robot can perform semantic mapping of such information while simultaneously identifying and locating objects [7] (see Figure. 8). During a later time of the mapping process, the acquired knowledge is used to avoid ambiguity in perceiving or searching the objects.

These research efforts address some critical challenges discussed early in the article, and act as a bridge between classical AI systems and physical robots. By solving these problems, we are advancing towards the goal of having a personal robot companion to serve Frank and make him a healthy breakfast.
Bio
Karthik Desingh is a Ph.D. candidate of Computer Science and Engineering at the University of Michigan. He works at The Laboratory for PROGRESS advised by Prof. Jenkins and is closely associated with Robotics Institute and Michigan AI. Desingh earned his B.E. in Electronics and Communication Engineering at Osmania University, India (2008), and M.S. in Computer Science at IIIT-Hyderabad (2013) and Brown University (2015). His research interests lie primarily in perception under uncertainty for goal-driven mobile manipulation tasks. Broadly towards solving problems in robotics and computer vision using probabilistic graphical models.
References
- Zhen Zeng, Zheming Zhou, Zhiqiang Sui, Odest Chadwicke Jenkins, Semantic Robot Programming for Goal-Directed Manipulation in Cluttered Scenes, ICRA 2018
- Generative Model, https://en.wikipedia.org/wiki/Generative_model
- Zhiqiang Sui, Lingzhu Xiang, Odest Chadwicke Jenkins, Karthik Desingh, Goal-directed Robot Manipulation through Axiomatic Scene Estimation, IJRR 2017
- Karthik Desingh, Odest Chadwicke Jenkins, Lionel Reveret, Zhiqiang Sui, Physically Plausible Scene Estimation for Manipulation in Clutter, Humanoids 2016
- Karthik Desingh Anthony Opipari, Odest Chadwicke Jenkins, Pull Message Passing for Nonparametric Belief Propagation, arXiv July 2018
- Karthik Desingh, Shiyang Lu, Anthony Opipari, Odest Chadwicke Jenkins, Factored Pose Estimation of Articulated Objects using Efficient Nonparametric Belief Propagation, ICRA 2019 (to appear)
- Zhen Zeng, Yunwen Zhou, Odest Chadwicke Jenkins, Karthik Desingh, Semantic Mapping with Simultaneous Object Detection and Localization, IROS 2018
- Karthik Desingh, Anthony Opipari, Odest Chadwicke Jenkins, Analysis of Goal-directed Manipulation in Clutter using Scene Graph Belief Propagation, ICRA 2018 Workshop
- Dai, Angela and Ritchie, Daniel and Bokeloh, Martin and Reed, Scott and Sturm, J{\”u}rgen and Nie{\ss}ner, Matthias}, Scan, Complete: Large-Scale Scene Completion and Semantic Segmentation for 3D Scans, CVPR 2018.
- Rodney Brooks, “Steps Towards Super Intelligence,” Blog post consisting of four parts.